Abstract
We introduce Toyteller, an AI-powered storytelling system where users generate a mix of story text and visuals by directly manipulating character symbols like they are toy-playing. Anthropomorphized symbol motions can convey rich and nuanced social interactions; Toyteller leverages these motions (1) to let users steer story text generation and (2) as a visual output format that accompanies story text. We enabled motion-steered text generation and text-steered motion generation by mapping motions and text onto a shared semantic space so that large language models and motion generation models can use it as a translational layer. Technical evaluations showed that Toyteller outperforms a competitive baseline, GPT-4o. Our user study identified that toy-playing helps express intentions difficult to verbalize. However, only motions could not express all user intentions, suggesting combining it with other modalities like language. We discuss the design space of toy-playing interactions and implications for technical HCI research on human-AI interaction.
Project video
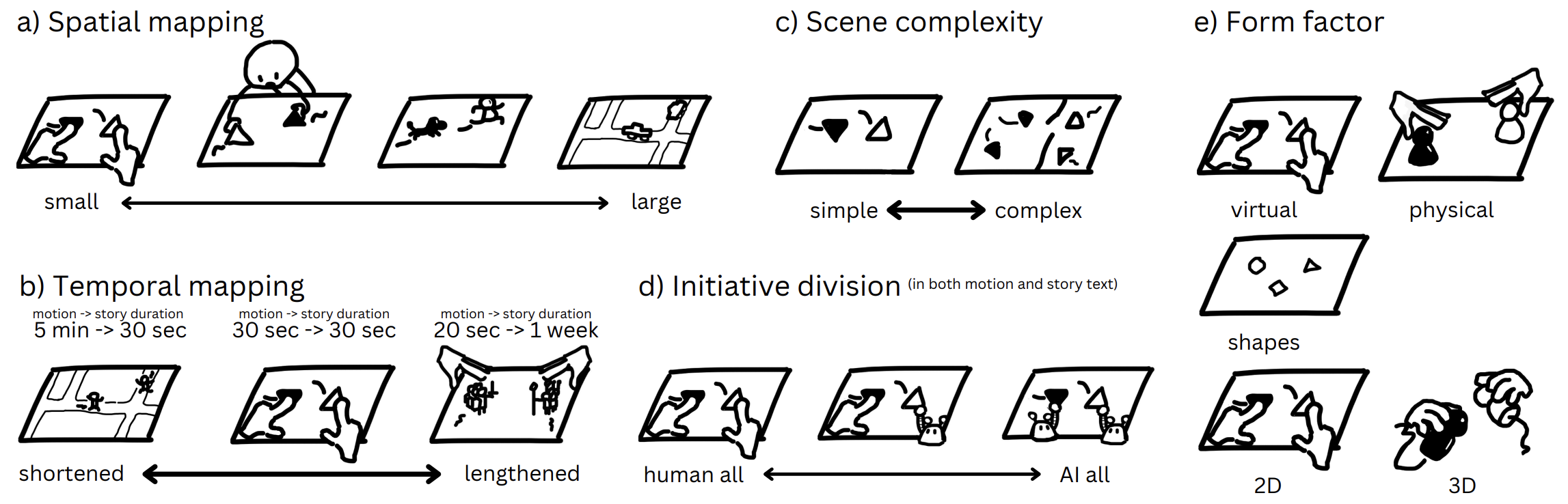
Core concept

🫱🧸🦖🤖What if we can do toy-playing with an AI to collaboratively tell a story?

🧸✨📜 Toyteller enables such an interaction of toy-playing-based storytelling with the power of generative AI.
Interaction
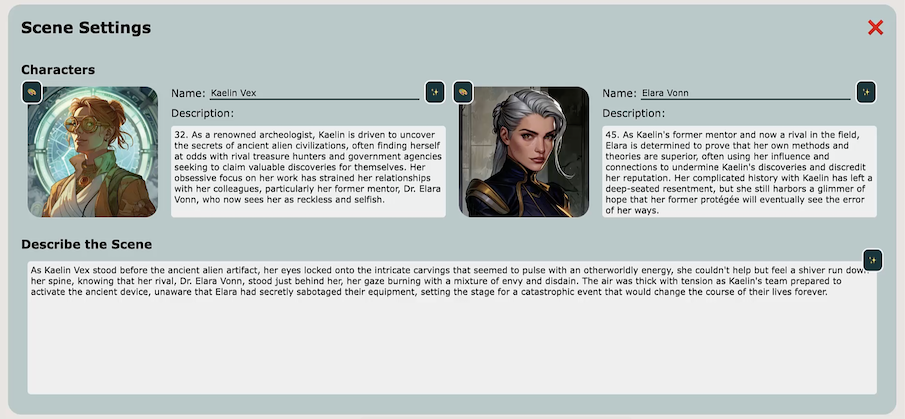
Then, in the tool, these characters will be rendered in character symbols, with which you can do toy-playing to generate stories.
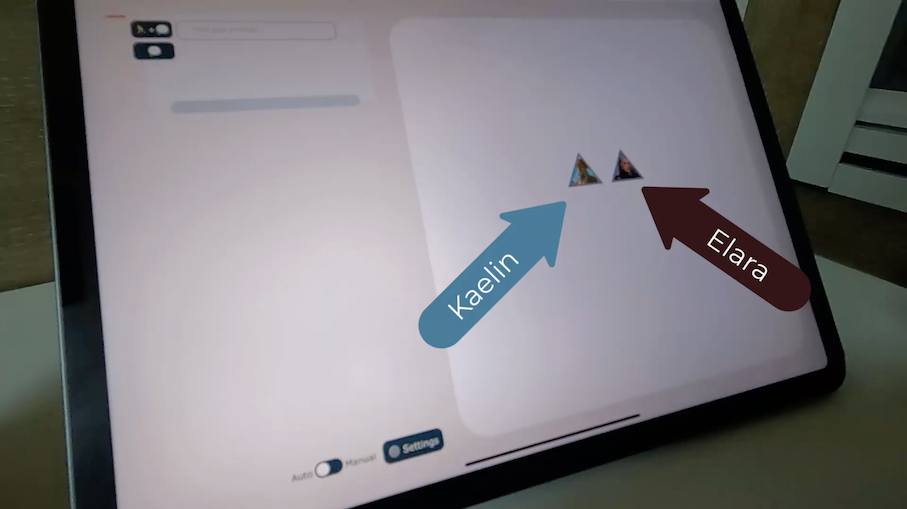
For example, you can move one symbol to another, AI-controlled symbol, and AI will try to generate a story sentence that goes along well with the motion.
You can also move two characters at once by yourself (in this case, one character chasing another) to make AI only generate the accompanying story sentence.
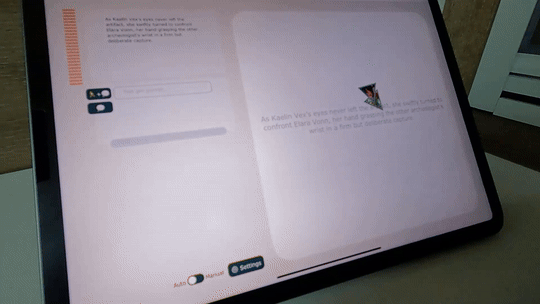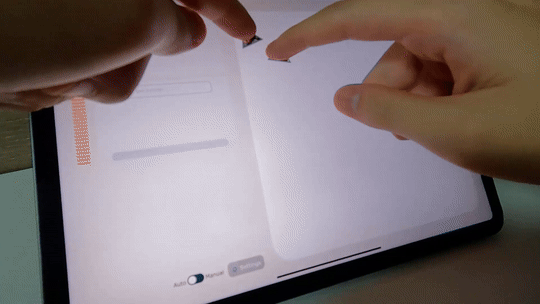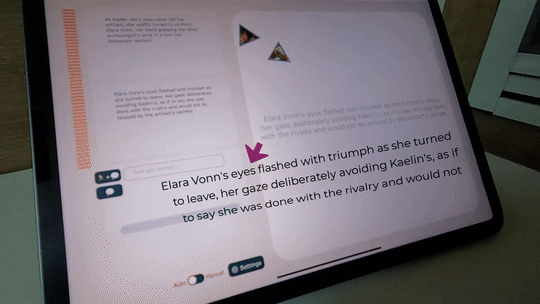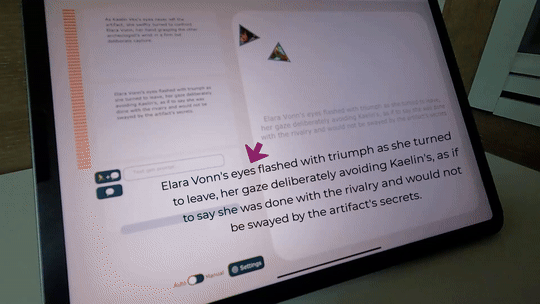
You can also make AI only generate motions based on the sentence you wrote, like below, where AI is generating fighting-like motions.

So, basically, with 🧸✨📜Toyteller, you can do flexible toy-playing-based story co-creation with AI.
Technical Overview
For such translation, we first tried to map the motions and texts onto the shared vector representaton of action information layer.
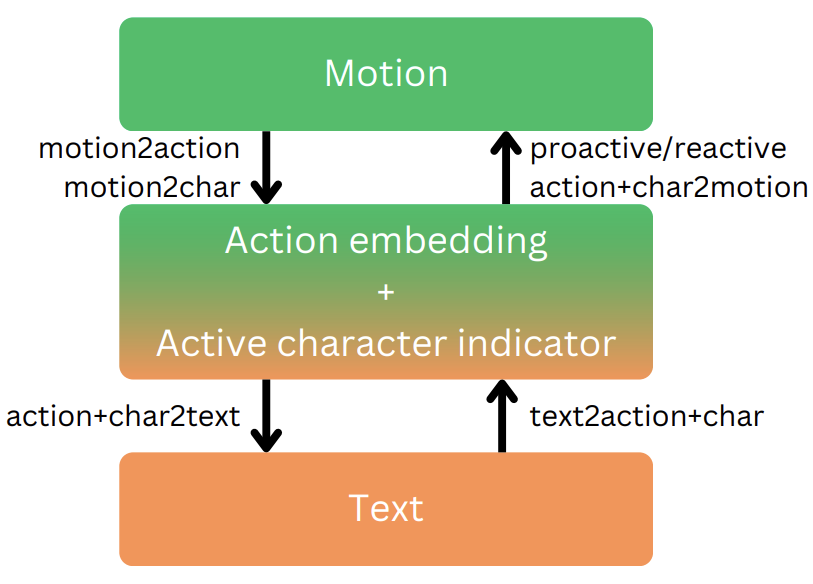 The action information layer consists of two pieces of information,
The action information layer consists of two pieces of information,
1) action embedding (action), which is about which event is happening between two characters, and
2) active character indicator (char), which is about who is the active agent of the action.
Note that action embedding is derived from existing text embedding vector space and active character indicator is binary boolean.
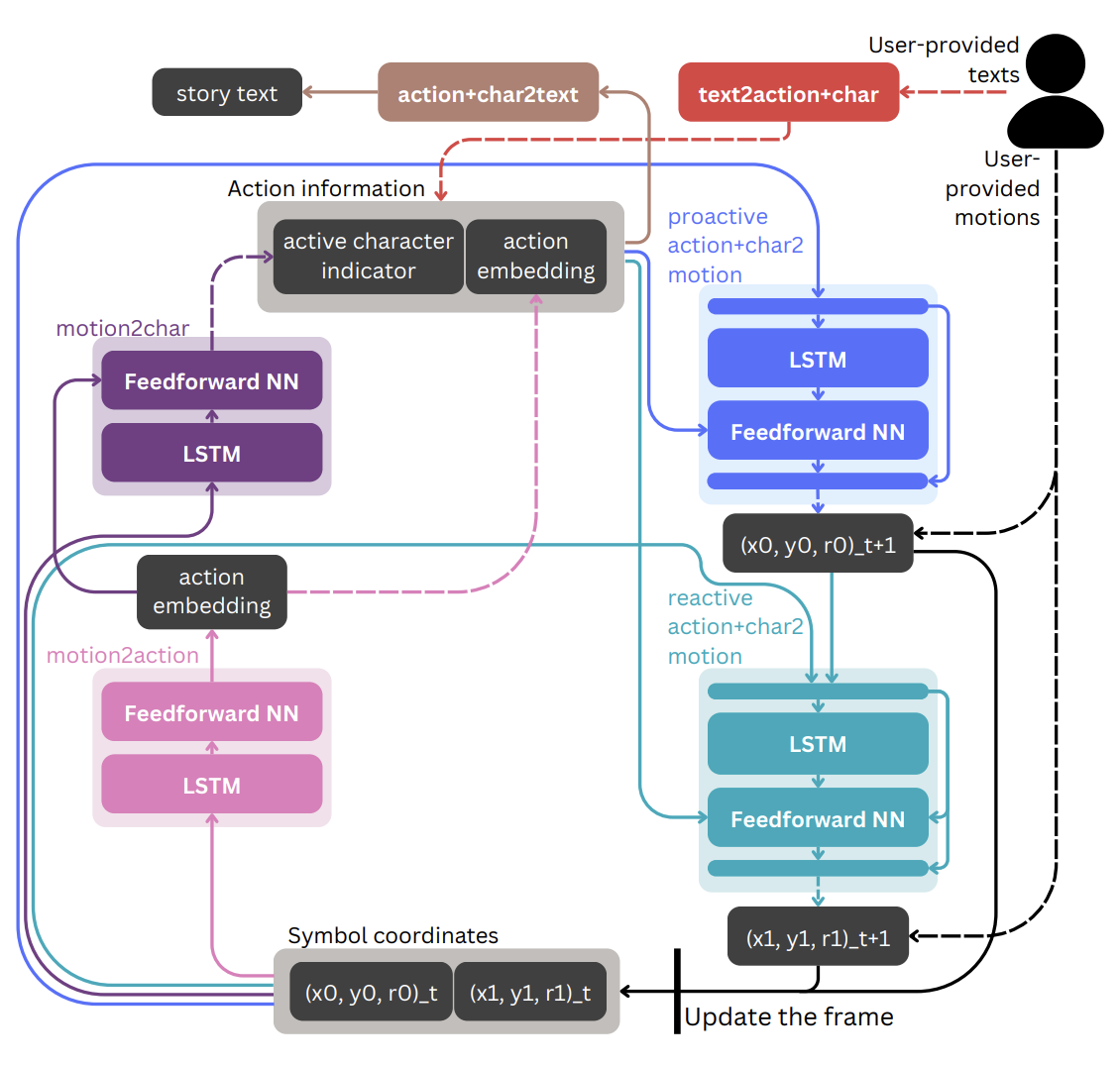 The task of translating motions to action information (motion2action and motion2char) is done by our trained LSTM models.
Generating motions out of action informaiton (proactive action+char2motion and proactive action+char2motion) is also done by training our LSTM models.
The task of translating motions to action information (motion2action and motion2char) is done by our trained LSTM models.
Generating motions out of action informaiton (proactive action+char2motion and proactive action+char2motion) is also done by training our LSTM models.
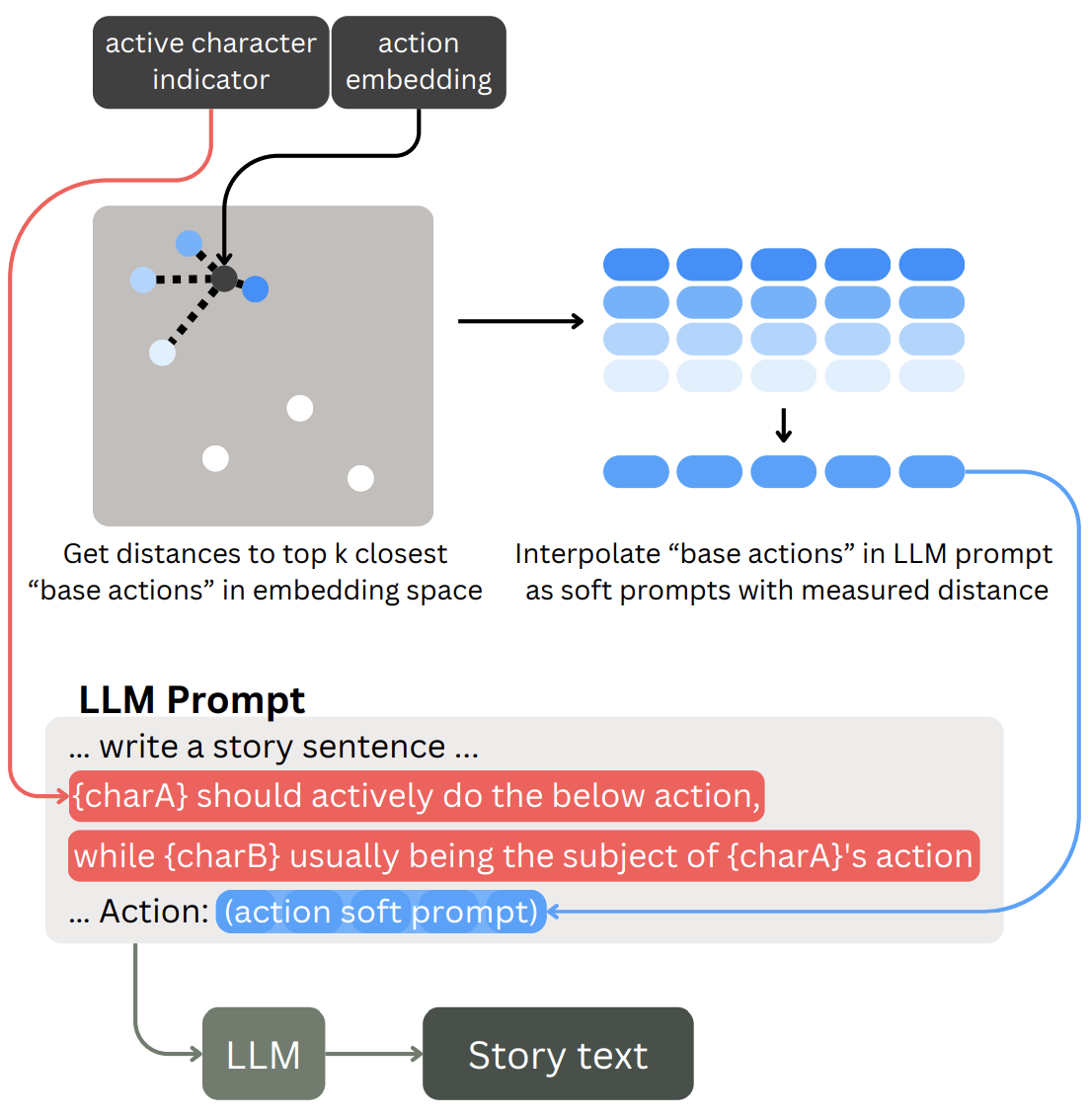 To generate texts out of action information (action+char2text in the overview diagram), we mapped action embeddings to soft prompts in the LLM's input embedding space, so that we can use it within the prompt to generate a story. Active character indicator was also reflected onto the story generation prompt.
To generate texts out of action information (action+char2text in the overview diagram), we mapped action embeddings to soft prompts in the LLM's input embedding space, so that we can use it within the prompt to generate a story. Active character indicator was also reflected onto the story generation prompt.
For translating texts into action information (text2action+char), we used a combination of text embedding models and LLM classifications.
Technical Evaluation
1) translating motions into action information (motion2action and motion2char),
2) generating story texts out of motions (motion2action and motion2char ➔ action+char2text), and
3) generating motions out of action information (proactive action+char2motion and proactive action+char2motion).
Overall, our system outperforms a competitive baseline, GPT-4o in many aspects.
 For 1) motion2action and motion2char, we evaluated if motion2action places gold standard actions in higher ranks (Action Rank) with more weights (Action Weight Ratio
to Top 1) in shorter times (Action Latency) compared to GPT-4o alternatives. We also compared motion2char to GPT-4o regarding
accuracy in classifying active characters (Character Correctness) and latency (Character Latency). GPT-4o-V uses motion images as input and GPT-4o-C uses textual coordinates as input.
For 1) motion2action and motion2char, we evaluated if motion2action places gold standard actions in higher ranks (Action Rank) with more weights (Action Weight Ratio
to Top 1) in shorter times (Action Latency) compared to GPT-4o alternatives. We also compared motion2char to GPT-4o regarding
accuracy in classifying active characters (Character Correctness) and latency (Character Latency). GPT-4o-V uses motion images as input and GPT-4o-C uses textual coordinates as input.
 For 2) motion2action and motion2char ➔ action+char2text, we assessed motion-text alignment, novelty/interestingness, coherence/grammaticality, latency, and diversity in text generation. Ours-top1 indicates the condition that does not use soft prompts.
For 2) motion2action and motion2char ➔ action+char2text, we assessed motion-text alignment, novelty/interestingness, coherence/grammaticality, latency, and diversity in text generation. Ours-top1 indicates the condition that does not use soft prompts.
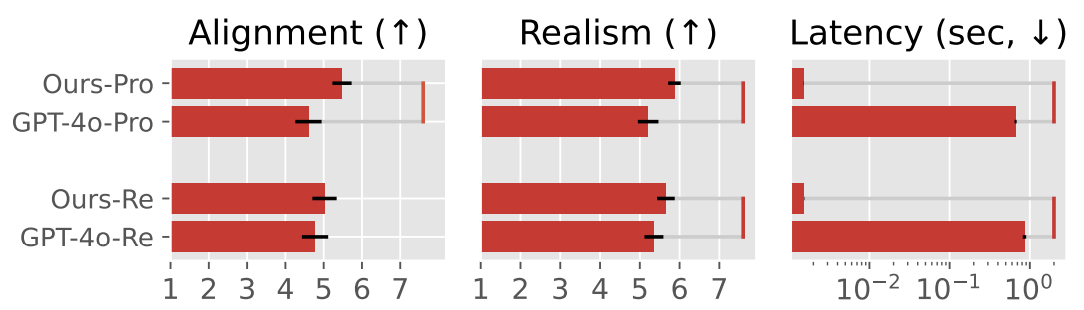 For 3) proactive action+char2motion and proactive action+char2motion, we evaluated alignment between actions and motions, realism of the motion (e.g., the motion does not have drastic jitters), and latency.
For 3) proactive action+char2motion and proactive action+char2motion, we evaluated alignment between actions and motions, realism of the motion (e.g., the motion does not have drastic jitters), and latency.
Generated Samples
White - Nolly (who dislike Paul)
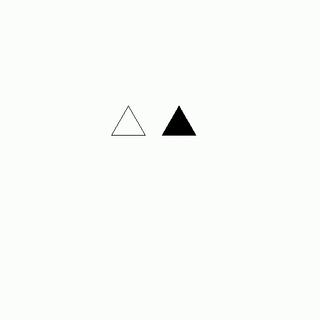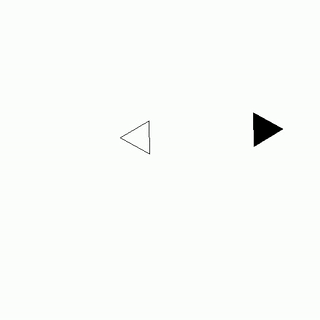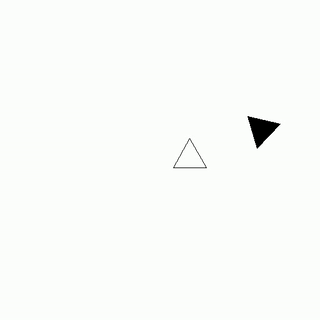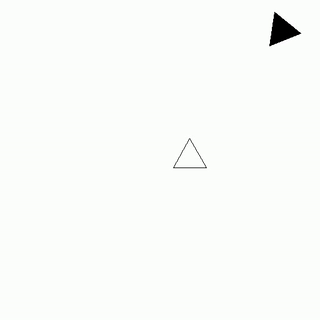
As Paul tried to leave the party, Nolly, who disliked him intensely, began to loudly whisper his name, causing Paul to feel embarrassed and eventually forced to leave, effectively being chased away by Nolly's unwanted attention.
White - Zephyr Astro
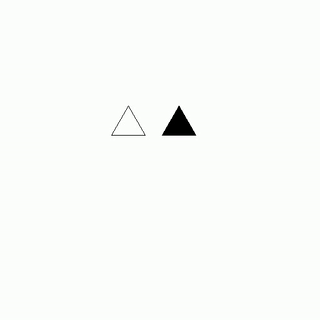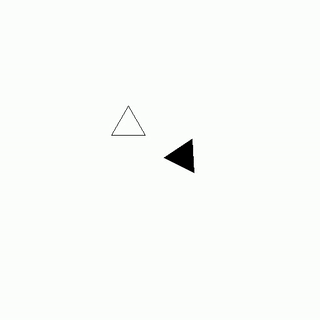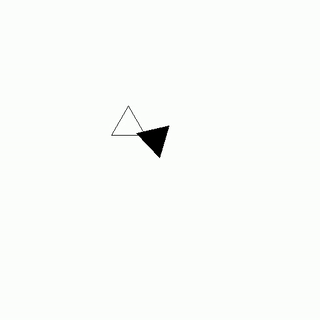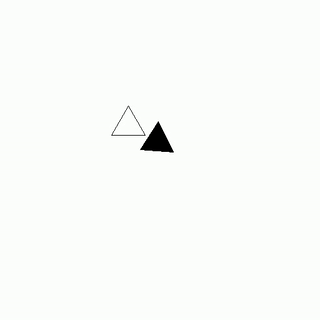
As the gravity generators sputtered to life, Lyra Novax leaned in close to Zephyr Astro's ear and whispered, "Zeph, I've got the hack in place, now let's get out of here before the security forces follow our trail."
White - Amy
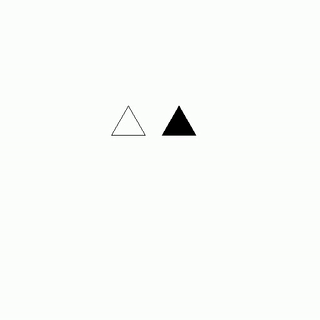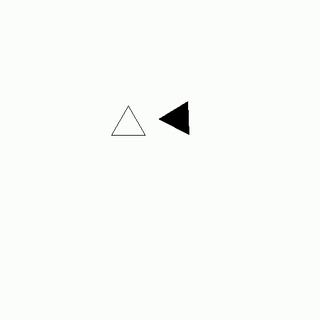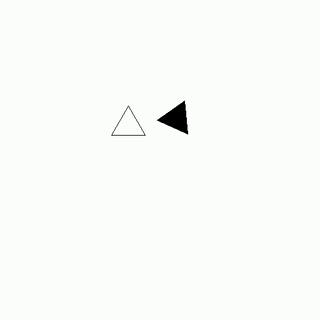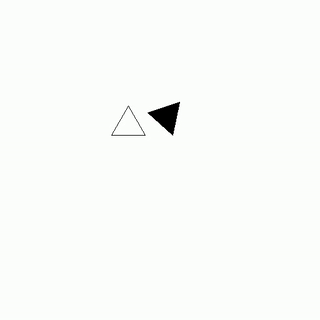
As Jack's fingers danced across the worn wooden keys, he passionately argued with Amy about the merits of their favorite novel, his words pouring out in a fervent plea to sway her opinion.
User Study
Toy-playing was more adequate for expressing motion/action-related nuanced ideas or under-developed ideas that are yet hard to verbalize.
On the other hand, natural language prompting was more adequate if the user wants to be specific on aspects that is irrelevant to actions/motions.
As Toyteller allows users to use both interaction approaches, we could observe users using these approaches in mix, complementing these with each other.
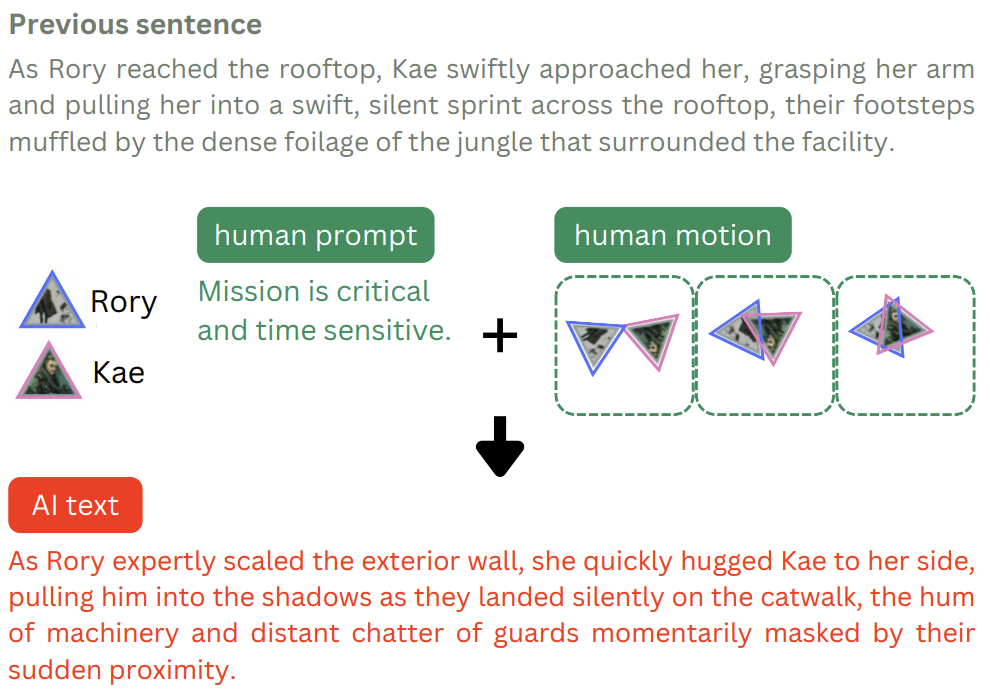 A case of mixing motion and natural language prompt inputs.
A case of mixing motion and natural language prompt inputs.
We could also observe users flexibly dividing roles with AI in terms of which aspects of artifacts will be created by whom.
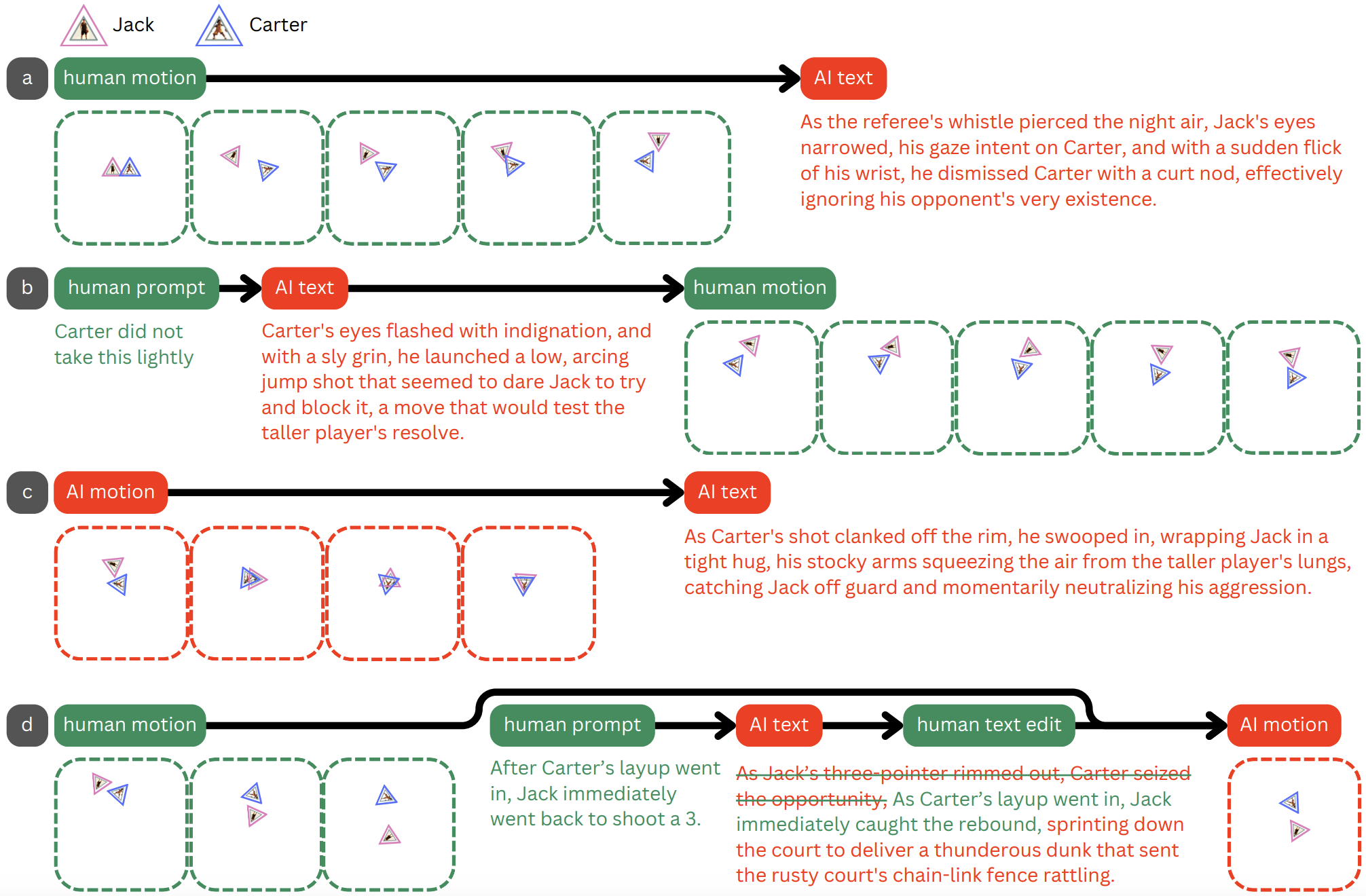 Various cases of user dividing roles with AI.
Various cases of user dividing roles with AI.
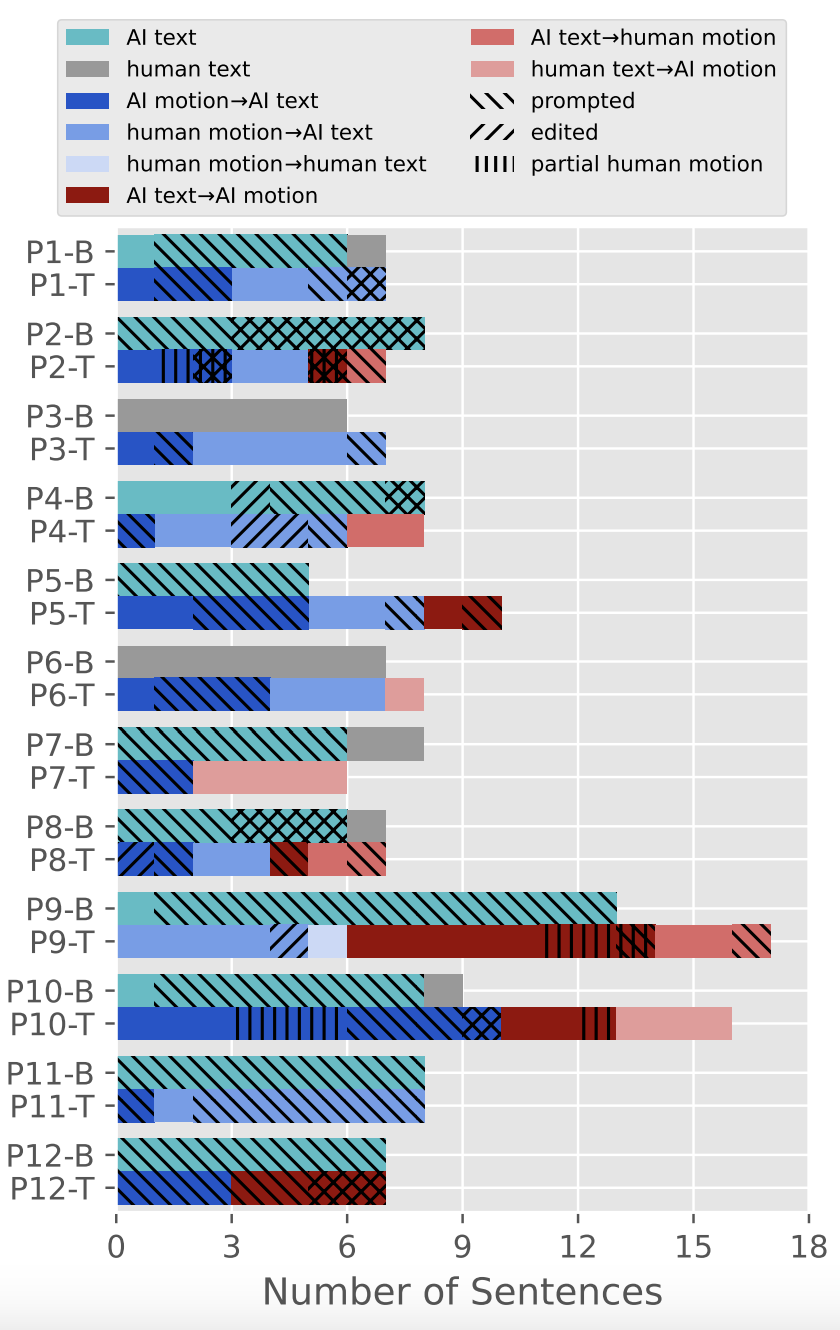 The distribution of how participants created story sentences and motions. ‘Prompted’ means that the user input conditioning natural language prompts when generating text, and ‘edited’ means that the user edited story text after AI generated them. ‘Partial human motion’ indicates both human and machine contributed to creating motions. ‘B’ and ‘T’ denote ‘baseline’ and ‘Toyteller’, respectively.
The distribution of how participants created story sentences and motions. ‘Prompted’ means that the user input conditioning natural language prompts when generating text, and ‘edited’ means that the user edited story text after AI generated them. ‘Partial human motion’ indicates both human and machine contributed to creating motions. ‘B’ and ‘T’ denote ‘baseline’ and ‘Toyteller’, respectively.
Design Space